`scipy.stats.t.interval` : 주어진 신뢰 수준에서 t-분포(밑에서 얘기하는 student t 분포)를 사용하여 신뢰 구간(confidence interval)을 계산하는 데 사용
alpha : 신뢰 수준(confidence level) ex.95% 신뢰 구간 -> 0.95로 설정
df : 자유도(degrees of freedom). 일반적으로 표본 크기에서 1을 뺀 값 (df = n - 1).
loc : 위치(parameter of location). 일반적으로 표본 평균
scale : 스케일(parameter of scale). 일반적으로 표본 표준 오차(standard error)
표본 표준 오차 : 표본 표준편차를 표본 크기의 제곱근으로 나눈 값 (scale = sample_std / sqrt(n)
scipy.stats.t.interval(alpha, df, loc=0, scale=1)
1. 정규분포
출처 : 위키백과
종 모양의 대칭 분포로, 대부분의 데이터가 평균 주위에 몰려 있는 분포
ex. 대부분의 사람들의 키와 몸무게는 정규분포를 따름, 큰 집단의 시험 점수는 정규분포를 따르는 경향이 있음
# 정규분포 생성
normal_dist = np.random.normal(170, 10, 1000)
# 히스토그램으로 시각화
plt.hist(normal_dist, bins=30, density=True, alpha=0.6, color='g')
# 정규분포 곡선 추가
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = stats.norm.pdf(x, 170, 10)
plt.plot(x, p, 'k', linewidth=2)
plt.title('normal distribution histogram')
plt.show()
2. 긴 꼬리 분포
출처 : https://www.nngroup.com/articles/long-tail/
대부분의 데이터가 분포의 한쪽 끝에 몰려 있고, 반대쪽으로 긴 꼬리가 이어지는 형태의 분포
ex. 소득 분포, 웹사이트 방문자 수
# 긴 꼬리 분포 생성 (예: 소득 데이터)
long_tail = np.random.exponential(1, 1000)
# 히스토그램으로 시각화
plt.hist(long_tail, bins=30, density=True, alpha=0.6, color='b')
plt.title('long tail distribution histogram')
plt.show()
3. 스튜던트 t 분포
출처 : 위키백과
정규분포와 유사하지만, 표본의 크기가 작을수록 꼬리가 두꺼워지는 특징
자유도가 커질 수록 정규분포에 가까워짐 (여기서 자유도란 표본의 크기와 관련이 있는 값이라고 이해!)
t분포는 모집단의 표준편차를 알 수 없고 표본의 크기가 작은 경우(일반적으로 30미만)에 사용되는 분포
ex. 새로운 약물의 효과를 테스트할 때, 소규모 임상 시험에서 두 그룹 간의 차이를 분석
# 스튜던트 t 분포 생성
t_dist = np.random.standard_t(df=10, size=1000)
# 히스토그램으로 시각화
plt.hist(t_dist, bins=30, density=True, alpha=0.6, color='r')
# 스튜던트 t 분포 곡선 추가
x = np.linspace(-4, 4, 100)
p = stats.t.pdf(x, df=10)
plt.plot(x, p, 'k', linewidth=2)
plt.title('student t distribution histogram')
plt.show()
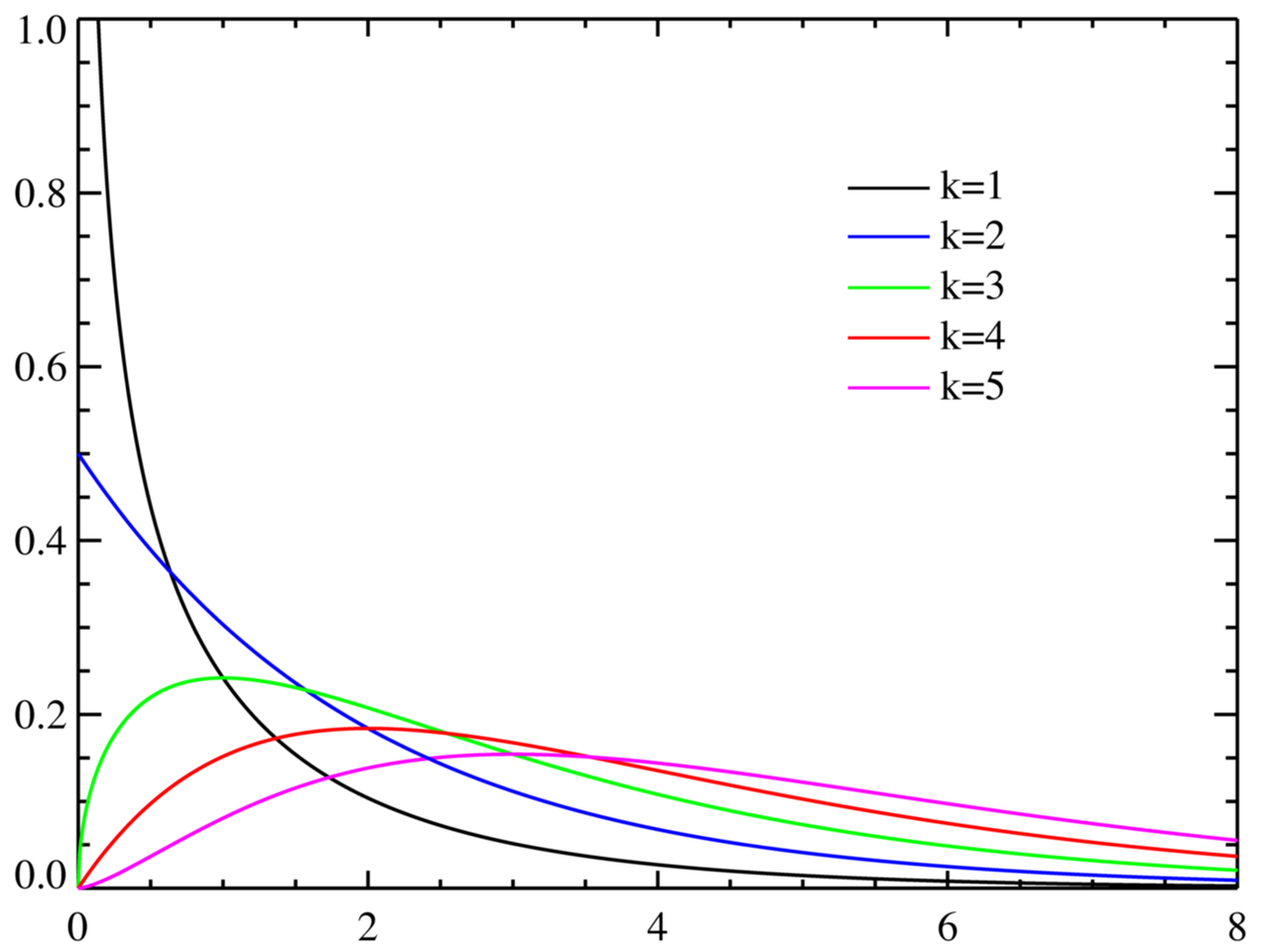
4. 카이제곱분포
출처 : 위키백과
`범주형 데이터`의 독립성 검정이나 적합도 검정에 사용되는 분포 -> 숫자형 데이터였으면 상관관계 보면 됨
K값은 자유도 (여기서 자유도란 표본의 크기와 관련이 있는 값이다 정도로 이해!)
자유도에 따라 모양이 달라짐
상관관계나 인과관계를 판별하고자 하는 원인의 독립변수가 ‘완벽하게 서로 다른 질적 자료’일 때 활용
ex) `독립성 검정` : 성별/나이에 따른 선거 후보 지지율 (유권자의 나이와 선거 후보는 독립변수지만 사실은 상관이 있다)
ex) `적합도 검정` : 주사위의 각 면이 동일한 확률(1/6)이어야 하는데 실제로 그렇게 나오는지 (관측값이 특정 분포에 해당하는지)
# 카이제곱분포 생성
chi2_dist = np.random.chisquare(df=2, size=1000)
# 히스토그램으로 시각화
plt.hist(chi2_dist, bins=30, density=True, alpha=0.6, color='m')
# 카이제곱분포 곡선 추가
x = np.linspace(0, 10, 100)
p = stats.chi2.pdf(x, df=2)
plt.plot(x, p, 'k', linewidth=2)
plt.title('카이제곱 분포 히스토그램')
plt.show()
5. 이항분포
성공/실패와 같은 두 가지 결과를 가지는 실험을 여러 번 반복했을 때 성공 횟수의 분포
연속된 값을 가지지 않고, 특정한 정수 값만을 가질 수 있음
이런 이항분포처럼 연속된 값을 가지지 않는 분포를 `이산형 분포`라고 지칭 하기도 함
데이터가 많아지면 정규분포에 가까워짐
ex. 결과가 2개만 나오는 상황을 여러번 하는 경우. 동전던지기, 무작위 100개 뽑아서 제품 불량률 모니터링
# 이항분포 생성 (예: 동전 던지기 10번 중 앞면이 나오는 횟수)
binom_dist = np.random.binomial(n=10, p=0.5, size=1000)
# 히스토그램으로 시각화
plt.hist(binom_dist, bins=10, density=True, alpha=0.6, color='y')
plt.title('이항 분포 히스토그램')
plt.show()
6. 푸아송분포
희귀한 사건이 발생할 때 사용하는 분포. 단위 시간 또는 단위 면적 당 발생하는 사건의 수를 모델링할 때 사용함
연속된 값을 가지지 않기 때문에 이 분포도 역시 `이산형 분포`에 해당함
평균 발생률 λ(람다)를 가진 사건이 주어진 시간 또는 공간 내에서 몇 번 발생하는지를 나타냄
평균 발생률 λ(람다)가 충분히 크면 정규분포에 가까워짐
ex. 특정 시간동안 콜센터에 도착한 전화의 수, 특정 도로 구간에서 일정 기간동안 발생하는 교통사고의 수
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import poisson
# 푸아송 분포 파라미터 설정
lambda_value = 4 # 평균 발생률
x = np.arange(0, 15) # 사건 발생 횟수 범위
# 푸아송 분포 확률 질량 함수 계산
poisson_pmf = poisson.pmf(x, lambda_value)
# 그래프 그리기
plt.figure(figsize=(10, 6))
plt.bar(x, poisson_pmf, alpha=0.6, color='b', label=f'Poisson PMF (lambda={lambda_value})')
plt.xlabel('Number of Events')
plt.ylabel('Probability')
plt.title('Poisson Distribution')
plt.legend()
plt.grid(True)
plt.show()
각종 분포 요약
정리
결국 데이터 수가 엄청 많아지면 정규분포에 수렴 (중심극한정리)
데이터 수가 많으면 묻지도 따지지도 말고 바로 정규분포로 가정!
하지만, 데이터가 적을 경우 각 상황에 맞는 분포를 선택
특히, long tail distribution은 데이터가 많아도 정규분포가 되지 않는 분포!